
Mbstring i PHP muszą być używane w tworzeniu aplikacji internetowych
Bajty i bity to dwie jednostki do przechowywania informacji logicznych. Bit można traktować jako jeden otwór, który można wypełnić jedną z dwóch wartości: 0 lub 1.
Bajt to grupa ośmiu bitów. Pod względem matematycznym bajt może reprezentować 256 różnych wartości (28).
Pomyślmy o języku, powiedzmy angielskim. Ma pewne znaki (a, b, c, … itd.), które są reprezentowane w komputerze przez bajty. Całkowita liczba znaków w języku angielskim nie przekracza 256, więc każdy znak można przedstawić za pomocą innej sekwencji 8-bitowej.
Ciągi to po prostu zbiór znaków. Normalnie w PHP operacje łańcuchowe działają na ciągach znaków jednobajtowych. Na przykład: możesz zechcieć porównać ciągi „Hello" i „Cześć”. Za pomocą strcmpr() oba ciągi zostaną porównane, zakładając, że każdy znak w ciągu zajmie jeden bajt.
Ale pomyśl o języku, który ma więcej niż 256 znaków (na przykład japoński) lub gdy chcemy reprezentować znaki z wielu języków jednocześnie. Jeden bajt pamięci dla każdego znaku to za mało. W tym miejscu pojawia się koncepcja wielobajtowa.
Łańcuch tekstu w języku japońskim może spowodować, że funkcja strcmpr() zwróci błędną lub śmieciową wartość, ponieważ założenie, że jeden bajt reprezentuje jeden znak, nie jest już prawdziwe. Kiedy pracujemy z łańcuchami zakodowanymi wielobajtowo, manipulowanie tymi łańcuchami wymaga raczej specjalnych funkcji niż typowych jednobajtowych funkcji ciągów. Aby poradzić sobie z łańcuchami wielobajtowymi w PHP, mbstring zapewnia wielobajtowe funkcje łańcuchowe.
Zrozumienie UTF-8
UTF oznacza Unicode Transformation Format i jest systemem kodowania, którego celem jest reprezentowanie każdego znaku w każdym języku w jednym zestawie znaków. Istnieją różne wersje UTF, z których niektóre pokazano poniżej:
| Format kodowania | Opis |
| UTF-1 | Kompatybilny z ISO-2022, przestarzały ze standardu Unicode. |
| UTF-7 | 7-bitowy system kodowania, używany głównie w wiadomościach e-mail, ale nie jest częścią standardu Unicode. |
| UTF-8 | 8-bitowy system kodowania, zmienna szerokość i zgodność z ASCII. |
| UTF-EBCDIC | 8-bitowy system kodowania, zmienna szerokość i zgodność z EBCDIC. |
| UTF-16 | 16-bitowy system kodowania, zmienna szerokość. |
| UTF-32 | 32-bitowy system kodowania, stała szerokość. |
Używamy UTF-8 przez większość czasu podczas pracy z tekstem wielobajtowym, więc skupmy się na tym przez chwilę. UTF-8 koduje znaki w wielu bajtach przy użyciu następującego schematu:
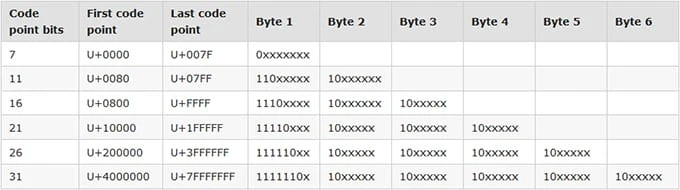
Skąd więc wie, czy znak jest przechowywany w jednym bajcie, czy w wielu bajtach? W tym celu sprawdza bit wyższego rzędu pierwszego bajtu.
| Kod | Oznaczający |
| 0xxxxxxx | Kod jednobajtowy |
| 110xxxxx | Po tym bajcie następuje jeszcze jeden bajt |
| 1110xxxx | Po tym bajcie następują dwa kolejne bajty |
| 11110xxx | Po tym bajcie następują kolejne trzy bajty |
| 111110xx | Po tym bajcie następują cztery kolejne bajty |
| 1111110x | Po tym bajcie następuje pięć kolejnych bajtów |
| 10xxxxxx | Kontynuacja znaku wielobajtowego |
Każdy kolejny bajt w wielobajtowej sekwencji zaczyna się od 1 i 0 w swoich dwóch najwyższych bitach, aby zapewnić sposób wykrywania uszkodzonych danych.
Wielobajtowe odpowiedniki wspólnych funkcji łańcuchowych
W przypadku powszechnie używanych funkcji łańcuchowych, takich jak strlen(), strops() i substr(), istnieją wielobajtowe funkcje równoważne. Powinieneś używać równoważnych funkcji podczas pracy z ciągami wielobajtowymi.
Tabela 4: Jednobajtowe równoważne wielobajtowe funkcje łańcuchowe
| Pojedynczy bajt | Wielobajtowe | Opis |
| strlen() | mb_strlen() | Uzyskaj długość łańcucha |
| strpos() | mb_strpos() | Znajdź pozycję pierwszego wystąpienia ciągu w ciągu |
| substr() | mb_substr() | Zwróć część ciągu |
| strtolower() | mb_strtolower() | Utwórz ciąg znaków małymi literami |
| strtoupper() | mb_strtoupper() | Zrób ciąg znaków wielkimi literami |
| substr_count() | mb_substr_count() | Policz liczbę wystąpień podciągów |
| podział() | mb_split() | Podziel łańcuch na tablicę za pomocą wyrażenia regularnego |
| Poczta() | mb_send_mail() | Wyślij zaszyfrowaną pocztę |
| erg() | mb_ereg() | Dopasowanie wyrażenia regularnego |
| robić() | mb_regi() | Dopasowanie wyrażenia regularnego bez uwzględniania wielkości liter |
Podam przykład użycia funkcji wielobajtowej:
-
Nazwa funkcji: int mb_strlen (string $str [, string $encoding ] )
-
Opis: Uzyskaj długość łańcucha.
-
Parametry: str (ciąg wejściowy, którego długość ma zostać określona)
kodowanie (kodowanie znaków)
-
Zwracana wartość: Liczba znaków ciągu wejściowego str z kodowaniem znaków encoding
-
Zwracany typ: int
Przykładowy kod: Oto przykładowy kod użycia funkcji mb_strlen. Tutaj ciąg wejściowy jest chińskim słowem i używane są trzy różne opcje kodowania znaków.
$ str ="大大";
echo mb_strlen ($ str, 'utf8' ).
echo mb_strlen ($ str, 'gbk' ).
echo mb_strlen ($ str, ' gb2312').Ograniczenia: UTF-8 ma pewne ograniczenia, takie jak-
- Teoretycznie największa długość znaków zakodowanych w UTF-8 to sześć bajtów.
- 0xFE i 0xFF nigdy nie są używane w tym kodowaniu.
Włącz mbstring z php.ini :
- Potwierdź istnienie pliku php_mbstring.dll w folderze ext.
- Odkomentuj ;extension=php_mbstring.dll z php.ini (tj. extension=php_mbstring.dll)
- Uruchom ponownie serwer.
Konfiguracja środowiska wykonawczego: Aby włączyć niektóre funkcje mbstring, należy zmienić niektóre ustawienia.
Tabela 5: Konfiguracje w pliku php.ini
| Nazwa | Domyślna wartość | Zmienna opcja |
| mbstring.język | neutralny | PHP_INI_SYSTEM | PHP_INI_PERDIR |
| mbstring.detect_order | ZERO | PHP_INI_ALL |
| mbstring.http_input | przechodzić | PHP_INI_ALL |
| mbstring.http_output | przechodzić | PHP_INI_ALL |
| mbstring.internal_encoding | ZERO | PHP_INI_ALL |
| mbstring.script_encoding | ZERO | PHP_INI_ALL |
| mbstring.substitute_character | ZERO | PHP_INI_ALL |
| mbstring.func_overload | 0 | PHP_INI_SYSTEM | PHP_INI_PERDIR |
| mbstring.encoding_translation | 0 | PHP_INI_SYSTEM | PHP_INI_PERDIR |
Wyjaśnienie opcji konfiguracyjnych:
„Opcja zmienna” określa wartość trybu zmiennego. Opisuje, jak i skąd można zmienić opcje mbstring. Oto znaczenie wartości trybu:
Tabela 6: Różne tryby zmian
| Tryb | Oznaczający |
| PHP_INI_SYSTEM | Wpis możemy ustawić za pomocą php.ini lub httpd.conf |
| PHP_INI_PERDIR | Wpis możemy ustawić za pomocą php.ini, .htaccess, httpd.conf lub .user.ini |
| PHP_INI_ALL | Wpis możemy ustawić z dowolnego miejsca |
| PHP_INI_USER | Wpis możemy ustawić za pomocą skryptu użytkownika. |
Jak zmienić ze skryptu użytkownika:
Możemy użyć następującego kodu, aby ustawić wewnętrzne kodowanie mbstring ze skryptu użytkownika:
<?php
ini_set('mbstring.internal_encoding', 'UTF-8');
?>Jak zmienić z php.ini:
Możemy edytować plik php.ini, aby ustawić niektóre opcje mbstring.
; Set default language
mbstring.language = Neutral; Set default language to Neutral(UTF-8) (default)
mbstring.language = English; Set default language to English
; Enabled HTTP input encoding translation.
mbstring.encoding_translation = On
; Set default HTTP input character encoding
mbstring.http_input = pass ; No conversion.
mbstring.http_input = auto ; Set HTTP input to autoNiektóre problemy związane z mbstring:
Korzystanie z funkcji mbstring może czasami powodować pewne nękanie. Omówię tutaj niektóre problemy związane z używaniem przeciążenia funkcji wielobajtowych. Pomyślmy o scenariuszu.
Włączyłeś opcję mbstring.func_overload w swoim pliku php.ini. Twoja praca idzie dobrze. Przeciążasz jednobajtową funkcję łańcuchową wielobajtowymi funkcjami łańcuchowymi. Ale co się stanie, jeśli będziesz potrzebować zewnętrznej biblioteki, która często używa jakiejś funkcji łańcuchowej?
Istnieje rozwiązanie tego problemu. Możesz użyć mbstring.internal_coding. Kiedy wywołasz jakąś zewnętrzną bibliotekę, użyje ona kodowania jednobajtowego, a po powrocie do twojego projektu zostanie zaimplementowane kodowanie wielobajtowe. Ale co się stanie, jeśli między twoim projektem a biblioteką zewnętrzną nastąpi wywołanie zwrotne? Tutaj zawodzi.
Musisz więc pamiętać o tych problemach podczas korzystania z opcji mbstring.
Znaczenie mbstring dla tworzenia stron internetowych:
Aby stworzyć jakąkolwiek międzynarodową aplikację internetową, użycie mbstring jest koniecznością. W przeciwnym razie Twoja aplikacja będzie ograniczona do niektórych krajów i języków. Jako programista sugeruję zdobyć trochę wiedzy w tej dziedzinie i stać się skutecznym programistą internetowym.
Comments are closed, but trackbacks and pingbacks are open.